Why you can stay ahead of competition with the 4th generation of data-driven NoCode technology

You might have heard that Lowcode/Nocode are rising fast as one of the most promising enablers of the digitalization, especially with the pandemic situation urging all organisations, public or private sectors to release various apps fast to keep track of staff, customers monitoring as well as keep business running as normal. However, one can be easily confused by so many lowcode/nocode products in the market and not really sure what would really benefit his/her particular company. Let’s take a look at the evolution history of lowcode/nocode first.
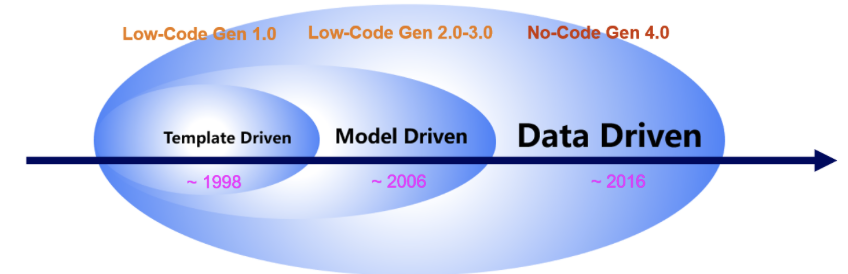
Lowcode appeared on the horizon around 30 years ago along with the internet hype where we all had some kind of encounter with the 1st generation of lowcode, which provides pre-stored templates to drag and drop to create some websites without knowing how to do coding. That’s the very first generation of lowcode, we call template-driven, or form-driven lowcodes. Still today in the lowcode market, a majority (around 95%) of lowcodes are based on this mechanism, but this type of template-based lowcodes is not very flexible to change already-set templates and certainly not capable for enterprise-class software development which demands highly complex operational process and logic building.
Then around 15 years ago came along a more advanced lowcode type called model-driven, today’s most dominant enterprise-class software development market is this type of lowcodes, as they brought along the model-building mechanism which enables much more complicated and sophisticated enterprise-class environment applications. These lowcodes represent the 2nd ”“ 3rd generation of lowcodes.
However this kind of lowcodes also has a serious drawback, which is inflexibility caused by human-created modelling. As it requires highly skilled IT professionals to build the data modelling to enable front end applications, whenever, yes we all know how often it happens, the front end user requirement changes, or new business situation arises, or any changes happened on the business front, the already-built modelling cannot work with the new changes anymore. With no choice, it demands the backend modelling to be rebuilt. However, in the data model, each data is linked with a complex web of data in a multitude of tables in database, a small change will involve a huge amount of work to redo the whole modelling, which demands not only highly skilled IT staff but also someone familiar with the original modelling, which poses the greatest difficulty for most companies, not to mention time and money to invest in. Therefore, the 2nd-3rd generation of model-driven is not flexible enough to cope with today’s VUCA era with bigdata environment.
When it comes to the 4th generation of data-driven NoCode technology, it takes a completely different and innovative approach to application development: leveraging integrated data sources from various operational IT systems and turn the data into data assets, it allows data to become highly intelligent and autonomous, can auto-detect relationship with data from heterogeneous data sources to create auto-data modelling, this automatic modelling by data themselves greatly eliminates the human intervention, reduced hefty skilled IT staff workload and ensures high level of flexibility, as the modelling can be broken down and rebuilt at any time- anywhere with front end requirement.
For data-driven NoCode, it also differentiates from lowcode in the aspect that Lowcode serves more target users of IT professionals by providing system generated coding for them to copy and paste into their programming, but Nocode removes the coding barrier once for all, that the users don’t have to know anything about coding and can drag and drop to build any workflow, analytical reports and applications according to their needs. This character means it allows not only non-IT business users to build their own bespoke workflow and applications they truly need and tend to use more frequently, but also can largely reduce the qualification for software developers for software vendors, reducing their personnel expense and therefore improve bottom line. On Average data-driven NoCode can deliver enterprise-class complex applications within 3-6 weeks with a handful of junior engineers, around 70% further lead time reduction from model-driven NoCode products, and even more from the traditional fully human coding (high code) software development lead time of 1-2 years.
Till now you must be able to realize, how much faster time-to-market and time-to-cashflow the bigdata powered NoCode can bring to the customers, that’s why in many cases start-ups and scale-ups can attract VC investment much more easily with Nocode platform built in.
Even with the IT skill barrier removed, it does not mean NoCode replaces the programmers. Instead, the programmers can be relieved from many hours of low-value-added mechanical coding work to focus on higher value-added business know-how and customer centric work, while delivering software and applications much faster, thus creating much more value for their companies.
So to wrap it up, you can see quite clearly what values one can get from the 4th generation of data-driven NoCode technology:
- Faster software development lead time (Average 3-6 weeks)
- Reduced IT skills = reduced personnel cost
- Great time-to-market and time-to-cashflow
- Eliminated data silo problem due to bigdata platform foundation (this is very important feature which we will have a dedicated article to talk about it, stay tuned in)
- Multi-party coordinated development as well as software building on-the-go with auto-modelling, what you see is what you get
- Enterprise-class competency and real big-data capabilities
- Highly improved profitability
- Non-IT business user friendly, higher success rate of applications built
Written By Shan You, SVP / MD for Overseas at Smardaten Technologies
Photo by Christina Morillo: https://www.pexels.com/photo/person-using-silver-macbook-pro-1181467/
What is on this page:
Related content

Building Trust in the Age of AI: How AFREEGUARD AI Is Redefining Ethical Intelligence

Financial Regulation Innovation Lab (FRIL) Innovation Case Study: Profylr
